Great write-up, Bill. Thanks.
We saw this on the ICCN as well (Illinois Regional Network) just like the rest of the folks that peer with NLR. We do pretty detailed instrumentation and metrics collecting on our networks, here are a few more graphs that show it in a bit more detail,
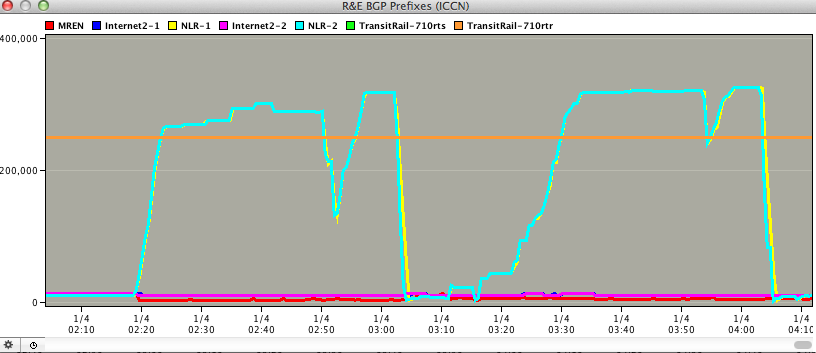
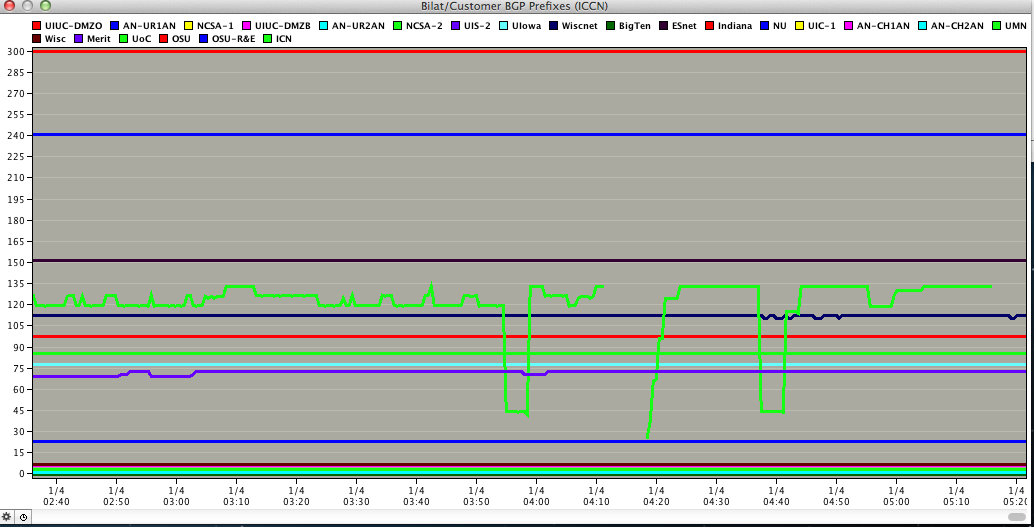
if nothing else it's somewhat interesting data for reference. The first one is the NLR announcement with a 10 minute average. The second is what the change did to the bilateral peerings, most of which come via the OmniPOP.
As you can see, UMN was hit pretty hard during this. Luckily we saw no real issue other than alarms/pages indicating routes exceeded thresholds.
---
Nick Buraglio
Lead Network Engineer
University of Illinois
P: 217.244.6428
http://bit.ly/ndb-calendar
AS38 AS40387 AS10932 AS32698
On Jan 4, 2013, at 3:37 PM, Bill Owens <>
wrote:
There was a short but very useful discussion of today's BGP problems taking place on the wg-multicast list, based on my initial (and incorrect) impression that the issue had something to do with multicast; Michael Lambert suggested that
I bring the thread here instead.
For those who weren't directly affected, here's what we've been able to figure out so far:
- At 0821 UTC today (Jan 4) an NLR maintenance went horribly wrong. There's been no public statement from them that I'm aware of, and despite having had an NLR connection for years we have never been able to get on any of their notification lists. But Michael
forwarded a note to wg-multicast with this:
"DESCRIPTION: Engineers encountered issues while upgrading the NLR Core
node in Atlanta which has resulted in prefixes being leaked out to several
peers and affecting the peering sessions. Engineers are still working on
resolving the issue. "
The NLR NOC Framenet maintenance calendar says that this morning they performed NLR Maintenance 4273: "DESCRIPTION: NLR Engineers will be performing IOS upgrade on the Cisco"
- The BGP prefix count for our NLR connection in NYC and our two I2 connections in NYC and Buffalo (via Chicago) went from <15k to >326k.
- Since our backbone consists entirely of 760x routers with non-XL daughtercards, the TCAM tables on the routers were immediately overrun:
Jan 4 08:21:46: %MLSCEF-DFC2-4-FIB_EXCEPTION_THRESHOLD: Hardware CEF entry usage is at 95% capacity for IPv4 unicast protocol.
Jan 4 08:21:50: %CFIB-SP-3-CFIB_EXCEPTION: FIB TCAM exception for IPv4 unicast. Packets through some routes will be dropped.
Use "mls cef maximum-routes" to modify the FIB TCAM partition or/and consider a hardware upgred.
Examine your network and collect the necessary information from this setup.
The only way to recover from this state is by reload the router.
Yes, the error message really says "upgred".
- As our backbone 7600s hit their limits, the smaller routers used by some of our campuses fell over completely. In the process of dealing with the flood of prefixes, even some of the larger routers dropped their sessions.
- Since the prefixes were for some subset of the commercial Internet, NLR became a black hole destination for a considerable amount of traffic. This was most pronounced for campuses who use localpref to force traffic onto their R&E connections. This is yet
another reason not to use localpref.
- Our own office router, a 7609 with Sup720B, was hit by the TCAM exhaustion as well, but we discovered that IPv6 connectivity still worked (yay IPv6!) and that allowed us to have some visibility into the network - but further confused the initial troubleshooting.
- It appears that the route leak lasted for some time, then went away, then came back. This wasn't at all obvious from our logs, but the attached graphs show it clearly. They are from a BGP prefix monitor set up by one of our member campuses, looking at their
connection to NYSERNet and their direct IP connection to NLR. Their routers are all 760x with XL cards, so they stayed up - but the bulk of their commercial traffic was siphoned off onto the NLR connection during the incident.
- By the time we had figured out what was going on, thanks in large part to triangulation from folks on the wg-multicast list and the cryptic but relevant Internet2 outage messages, the NLR route leak had stopped and the prefix counts were back to normal. Unfortunately
the TCAM problem persisted, so we rebooted each of our backbone routers in turn to clear it. Most of our member campuses also had to reboot their edge routers.
- Although NYSERNet does not supply commercial Internet access to our members, some of them saw commercial outages at the same time. We believe that these were caused by direct impact on routers that carried both connections, by iBGP traffic overwhelming the
other edge routers, by middleboxes being impacted, and in at least one case by a Cogent multihop eBGP session being knocked down when the traffic tried to go over NLR to reach the peer.
- We have now configured bgp maximum-prefix on all of our external peers. We resisted that for a long time - although we've used it as a safety measure for campus connections, we know that it is likely to cause problems as well, or make small problems into
large ones by dumping BGP sessions for momentary issues. However, we can't have another day like this. We chose a limit of 20000 for the large connections because we have a number of member campuses with very small routers, and a higher limit would risk affecting
them even if our backbone routers weren't impacted.
I think that's about it. I still have to write a report for our board of directors, but the network has been stable since about 0830 EST, and all of the member connections were back by 1200 EST (following reboots of their equipment).
Bill.
|