perfsonar-user - Re: [perfsonar-user] Re: Tests not running periodically
Subject: perfSONAR User Q&A and Other Discussion
List archive
- From: Casey Russell <>
- To: Andrew Lake <>
- Cc: "" <>
- Subject: Re: [perfsonar-user] Re: Tests not running periodically
- Date: Tue, 29 Aug 2017 12:25:31 -0500
- Ironport-phdr: 9a23:5CmYvR+RR4WtYP9uRHKM819IXTAuvvDOBiVQ1KB31uscTK2v8tzYMVDF4r011RmSDNWds6oMotGVmpioYXYH75eFvSJKW713fDhBt/8rmRc9CtWOE0zxIa2iRSU7GMNfSA0tpCnjYgBaF8nkelLdvGC54yIMFRXjLwp1Ifn+FpLPg8it2e2//57ebx9UiDahfLh/MAi4oQLNu8cMnIBsMLwxyhzHontJf+RZ22ZlLk+Nkhj/+8m94odt/zxftPw9+cFAV776f7kjQrxDEDsmKWE169b1uhTFUACC+2ETUmQSkhpPHgjF8BT3VYr/vyfmquZw3jSRMMvrRr42RDui9b9mRx3miCkHOTA383zZhNJsg69ApRKtuwZyzpTIbI2JNvdzeL7Wc9MARWpGW8ZcTzJMDZmnb4QRD+sKIPpWr5Tmp1sVsxS+AQ2sD/7oxzBUnH/2wLY60/8/HgHC2AwtBNEOv27SrNXvKqgSV/q5zK/WwjXfdv5b3yr25obPchAku/6MXLRwfNLVyUkuEQPFjUufppHkPzOTzOgCr2+b7+94WeKzhW8nqh1xoiSxycc2kIXGmoUVylXc+SV62ok1I8e4R1B9YdK+FptfqT2aOo1rSc0hW2FloDg2x7watZO5eSUKxpcqyAXDZ/GCfIWE/g7vW/qULDhkmH5oeLeyihOs/UWuy+DxUNS/3kxQoSpfiNbMs2gA1xzN5ciDTftw5kKh1iyO1wDX8+1EP0M0mbbCJ58u3LI9mJsevV7MHi/xn0X2g6uWeVs+9ue07OTnZ63qpp6aN4BqlgHzKroil82jDek6NwUOUWuW9v+g2LDm8kD1XKlGgeEzn6bFrJzXJcEWq6unDwJb04sv8xO/AC2n0NQck3kHNlVFeBefgof1IVHOPev4DeyhjFSolDdm3PPGMafnApXXMHfDlq3tfbBj5E5A0AYz18xQ54pICrEdJ/L+Qlfxu8LCDh83KAy0xODnB89n1o8HRGKPGbGWMLnJvF+M5+IvOPWMZJQLtDrnKvgl4eLugmEjmV8bY6apwYUbZGqmEft7PkXKKUbr1/4HHX0HoUIaRe/nwAmLVzJCT3upGaQx+mdoJpihCNLoT5ugkfS7wTygE5lSLjRNEE2XCnrsc62HUvEWZSTUJMJ9xG9XHYO9QpMsgEn9/DTxzKBqe7LZ
Andy,
Thanks for the fixed links. I found correct links a few days ago, similar to the ones you attached (Unable to get participant data), but clearly grabbed the wrong ones when putting the email together yesterday.
I don't recall it happening before the 16th, but it's possible it happened, just less occasionally. It does appear to always involve one of our lower powered hosts (we have 4 hosts that are single RU Dell servers). They have a single dual-core CPU and 8Gigs of RAM. Each host has two NICs, one for Latency tests and one for Bandwidth tests. Each NIC (and hostname) has individual IPv4 and IPv6 addresses. Specs are below:
[crussell@ps-fhsu-bw ~]$ cat /proc/cpuinfo | grep 'cpu\|processor\|model\|cache'
processor : 0
cpu family : 6
model : 37
model name : Intel(R) Celeron(R) CPU G1101 @ 2.27GHz
cpu MHz : 2261.082
cache size : 2048 KB
cpu cores : 2
cpuid level : 11
cache_alignment : 64
processor : 1
cpu family : 6
model : 37
model name : Intel(R) Celeron(R) CPU G1101 @ 2.27GHz
cpu MHz : 2261.082
cache size : 2048 KB
cpu cores : 2
cpuid level : 11
cache_alignment : 64
[crussell@ps-fhsu-bw ~]$ free -h
total used free shared buff/cache available
Mem: 7.6G 3.9G 548M 471M 3.2G 2.9G
Swap: 7.9G 316M 7.6G
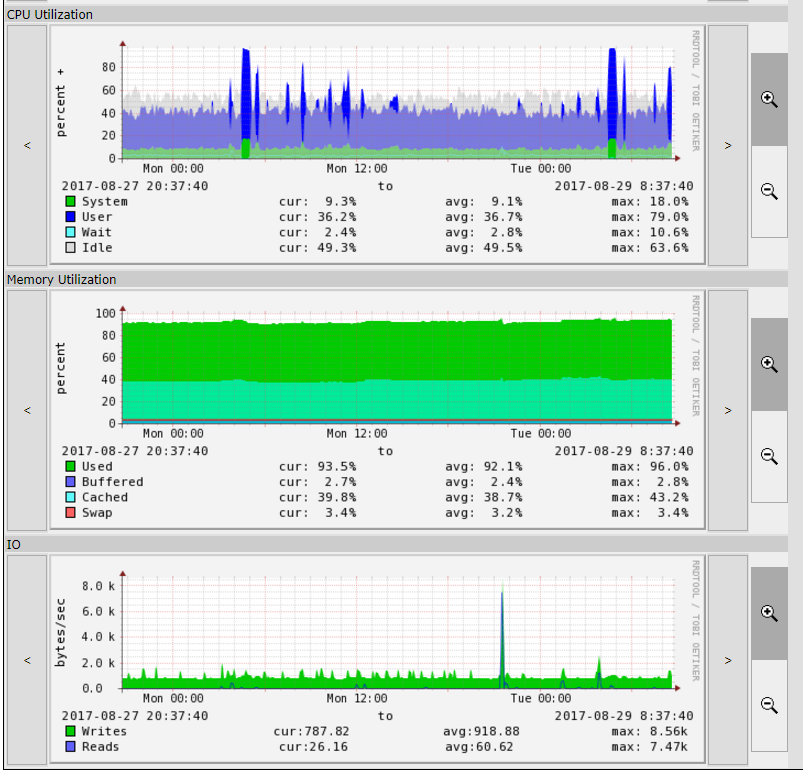
So it seems likely that these hosts are doing something at the moment of the perfsonar-meshconfig-agent run that prevents them from scheduling. As you can see from the performance graphs I've included, the CPUs aren't hammered ALL the time, but those are 5-minute averages, so a lot of short spikes can be hidden in those graphs. I'll watch and see if I can get more fine-grained data from "top" or something like it to see what might be causing them to error out during the run. Since the memory is well above the minimum requirements and rarely seems tapped out, I suspect it's more likely CPU related. These hosts just might be near the end of their days doing this work.
I'll let you know if I can find a likely culprit. Thank you for the info.
Sincerely,
Casey Russell
Network Engineer

2029 Becker Drive, Suite 282
Lawrence, Kansas 66047
Lawrence, Kansas 66047
On Tue, Aug 29, 2017 at 9:27 AM, Andrew Lake <> wrote:
Hi Casey,Thanks for all the info. It indeed looks like you are hitting some timeout issue. For reference, it looks like the broken run for the test you shared is actually https://ps-fhsu-lt.perfsonar.kanren.net/ . The one you shared looks to have completed successfully but that was the IPv4 task which looked good at the time, and what was broken at that time was the IPv6 task. It does not appear to be an IPv4 vs IPv6 issue as there is currently IPv4 tasks broken in the same way as well (e.g. https://ps-washburn-lt.pscheduler/tasks/f4c1d01f- 08f0-4e24-a92b-9298a223516c/ runs/58d5fed2-cbb2-403c-95b8- a5d1c5188047 perfsonar.kanren.net/ ).pscheduler/tasks/0cdcb1a2- 5f07-4d1a-b6cc-6a8ea0af317c/ runs/44bd3736-8f06-438e-b48f- 5ee66eeff910 As you noted after 24 hours they generally appear to fix themselves. This is because ther perfsonar-meshconfig-agent, the program reponsible for creating the tasks in pscheduler, creates the tasks with an end time 24 hours in the future. It will then recreate the task again in 24 hours. The OWAMP tests run using the tool “powstream" are a bit special in how they get scheduled. Since they run all the time, there is an initial run that is put on the schedule by pscheduler that’s really just a placeholder to indicate there is a task that should be running. Subsequent runs are actually posted by powstream as it gets results. If for whatever reason that initial run fails, then powstream never gets started. Currently, the mesh-config doesn't detect when this happens, so when it breaks like this the task will sit broken for 24 hours until mesh-config creates a new task. It looks like in your case there are occasionally timeouts trying to schedule the task likely due to a busy host. In summary, there are two things going on here:1. Your host is too busy for some reason, at least at certain times, which is causing timeouts. I am not sure why 4.0.1 would make this worse, we actually decreased the CPU a bit in our testing by adding some bulk requests to the mesh-config, reducing the I/O it was doing. Are these hosts tight on memory? Perhaps this is causing something to go to swap that wasn’t before? That’s just a guess and it’s of course possible something slipped up in other areas that we missed but unfortunately I don’t know anything “new” that would cause this behavior. I do notice that your hosts appear to be writing to a local and central archive. This is a perfectly reasonable thing to do, but archiving is the most CPU intensive operation we do currently but that is not new as of 4.0.1. We actually have a fix for this coming in 4.0.2 that changes how we spawn archiving processes and are showing some pretty significant performance gains, but this is still a month+ away from beta (so not much good to you in the immediate term).2. The other problem is that the meshconfig-agent is not detecting this problem so it takes 24 hours to fix. It’s not a “bug” in the sense that the behavior is unexpected, but it is something we need to figure out how to do better without hurting performance in other ways. Again not a solution for the immediate term unfortunately.Sorry this got kinda long and double sorry I don't have an immediate answer. We do appreciate you taking the time to dig through the API and trying to figure this out, but looks like you hit a tricky problem.Thanks,Andy
On August 28, 2017 at 3:19:34 PM, Casey Russell () wrote:
Sorry, it might be helpful to see my maddash grid in case you'd like to see other failed tests in the grid.
Sincerely,Casey RussellNetwork Engineer2029 Becker Drive, Suite 282
Lawrence, Kansas 66047


On Mon, Aug 28, 2017 at 2:17 PM, Casey Russell <> wrote:
Group,I've held off sending this to the group, because I was determined I was going to solve this one myself. However, the beginning of the semester is upon us and I just haven't had the time to devote. So here it goes, I'm asking for help. This seems similar, but perhaps not the same as Mark Maciolek's current thread, but since I'm not certain, I didn't tie it to that thread.I've got an entire Mesh that has started to randomly start failing tests. What I mean by that is this. Each day about 1/6 to 1/4 of the tests in the mesh will fail to run. When a test between two hosts will fail, it will always fail at the same time of day... stay failed until exactly the same time the next day, then start working again. And at that same time, a random sampling of other tests in the mesh will fail. (because my hosts hate me apparently).The first instance of failures I can find happened just after the 16th of August and my hosts are running auto updates. Which is why I keyed in on Mark's post. The failures start/swap each day just after noon. When I use the API to look and see what failed with the run, I see either a very generic "participant-data-full" or (paraphrasing here) "participant data unavailable" timeout sort of error.Here are some reference URLsFirst instance I can find (just after the 16th of August)Current example: (failed at the moment 2:13pm CDT Aug 28th)API "tasks" page:API "runs" page:It seems like something is busy, or the API is temporarily unavailable, when the host (or hosts) are pulling the new Mesh and scheduling tests, but I've run dry trying to figure out how to troubleshoot the individual pieces of that.
Sincerely,Casey RussellNetwork Engineer2029 Becker Drive, Suite 282
Lawrence, Kansas 66047
Attachment:
ps-esu-bw.PNG
Description: PNG image
{kind=link}
- [perfsonar-user] Tests not running periodically, Casey Russell, 08/28/2017
- [perfsonar-user] Re: Tests not running periodically, Casey Russell, 08/28/2017
- Re: [perfsonar-user] Re: Tests not running periodically, Andrew Lake, 08/29/2017
- Re: [perfsonar-user] Re: Tests not running periodically, Casey Russell, 08/29/2017
- Re: [perfsonar-user] Re: Tests not running periodically, Andrew Lake, 08/29/2017
- [perfsonar-user] Re: Tests not running periodically, Casey Russell, 08/28/2017
Archive powered by MHonArc 2.6.19.